Riffusion: Una variante de Stable Diffusion para crear música con inteligencia artificial
Y todo comienza con una poco de texto…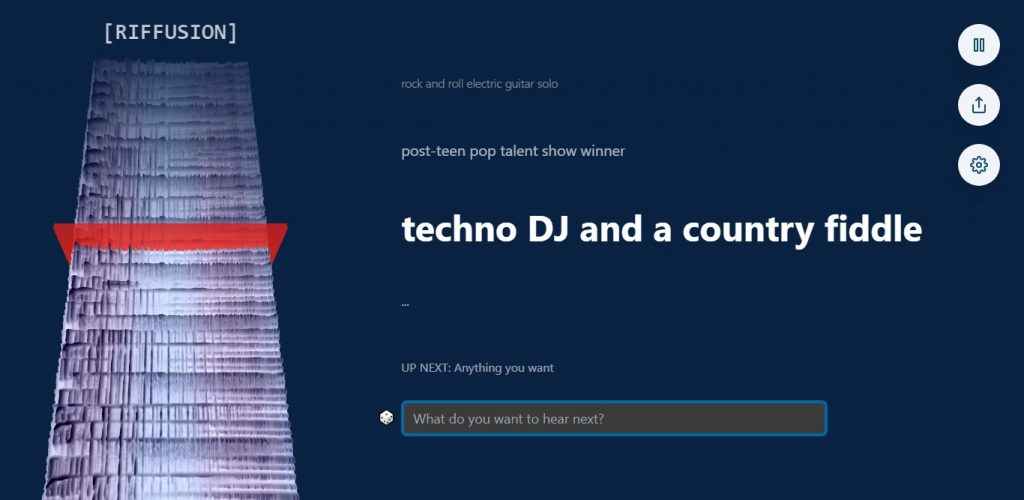
Los desarrolladores de plataformas generativas se adaptan a nuevas exigencias. Los entusiastas y los artistas «combaten» en redes sociales. Y entre todo ese caos surgen nuevos proyectos basados en inteligencia artificial. Uno de ellos es Riffusion, que utiliza una versión optimizada de Stable Diffusion para crear espectrogramas, representaciones visuales de sonido que podemos escuchar fácilmente.
Imágenes, vídeos, voces, música. Los proyectos de inteligencia artificial siguen evolucionando… con opiniones a favor y en contra. Recientemente hemos visto protestas, muchos «intercambios» que equivalen a ladrillazos digitales, y enormes dudas en materia de copyright y fair use. Tarde o temprano, los conflictos legales llegarán a instancias superiores, pero independientemente de lo que suceda, la inteligencia artificial continuará sorprendiéndonos.
Hoy es el turno de una nueva plataforma generativa llamada Riffusion, desarrollada por Seth Forsgren y Hayk Martiros. Tal y como lo sugiere su nombre, Riffusion tiene alma de Stable Diffusion, con una diferencia: El modelo fue especialmente optimizado para generar sonogramas/espectrogramas. En otras palabras, representaciones visuales de audio basadas en prompts de texto.
Riffusion: De texto a audio con inteligencia artificial
Ingresa un prompt, y deja que el modelo haga el resto
La página no requiere ninguna clase de cuenta, ni la compra de tokens para generar sonidos. De hecho, recomienda al usuario que experimente ingresando sus estilos e instrumentos favoritos. Las combinaciones son definitivamente bienvenidas, por ejemplo, «gospel tropical». También es posible crear prompts que indiquen la presencia de voces (uno de los más interesantes que encontré fue «post-teen pop talent show winner»), pero no debemos esperar ningún diálogo claro.
El sonograma/espectrograma es fácil de interpretar: El eje X representa el tiempo, el eje Y la frecuencia de los sonidos, y el color de cada píxel su amplitud. La última fase queda a cargo de Torchaudio, que toma la imagen generada por Stable Diffusion, y la convierte en audio. La sección About de Riffusion es excelente, y merece tu atención.
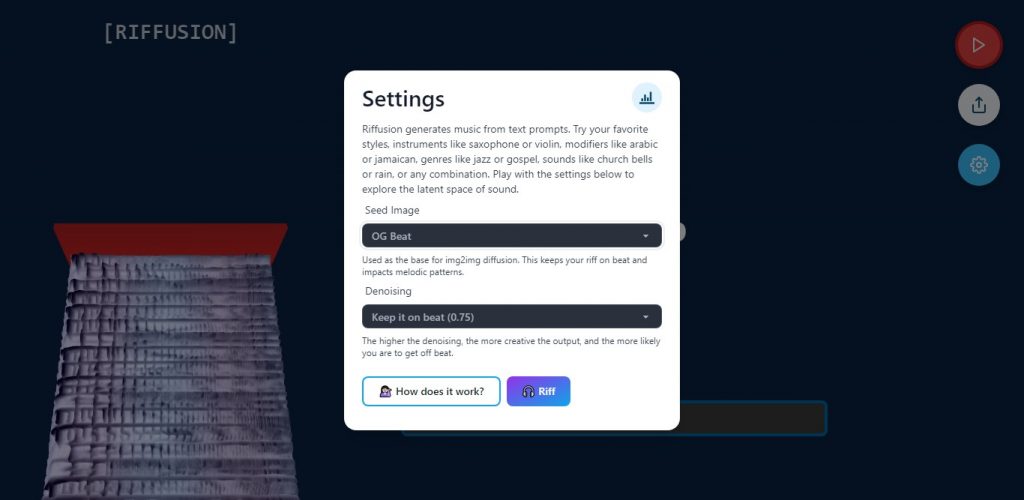
Al igual que en otros modelos, puedes alterar el seed y el nivel de denoising
La configuración avanzada nos permite cambiar la imagen que sirve como seed (cinco opciones diferentes), y el nivel de denoising. Cuanto más alto es, más «creativo» resulta su output… pero se alejará de lo que quieres. Este comportamiento es idéntico al de Stable Diffusion procesando imágenes. Otra cosa que toma prestada es el peso de los prompts. Por ejemplo, un énfasis en violines puede ser escrito como (violin:1.25) entre paréntesis, o corchetes para minimizar su impacto: [violin] equivale a una reducción de 1.1x.
Para finalizar, el servidor de Riffusion está siendo bombardeado con solicitudes, por lo tanto, hay que armarse de paciencia. También necesitarás buena aceleración de hardware en tu navegador, porque el sitio oficial es bastante exigente. ¡Haz la prueba!
Sitio oficial: Haz clic aquí


