Inteligencia artificial que sin ayuda humana identifica qué está haciendo la gente
Los humanos observamos el mundo mediante una combinación de diferentes modalidades de información, como por ejemplo las que nos proporcionan la visión o el oído, y también nos valemos de nuestra comprensión del lenguaje. Las máquinas, en cambio, interpretan el mundo a través de datos que deben ser procesables mediante algoritmos.
Así, cuando una máquina “ve” una foto, debe codificarla en datos que pueda utilizar para realizar una tarea como la clasificación de imágenes. Este proceso se complica cuando la información llega en múltiples formatos, como por ejemplo vídeos, clips de audio e imágenes.
El principal reto en tal caso es cómo puede una máquina combinar esas diferentes modalidades. Como humanos, esto es fácil para nosotros. Vemos un coche y oímos el sonido de un coche pasando, y sabemos que son la misma cosa. Pero para la inteligencia artificial no es tan sencillo.
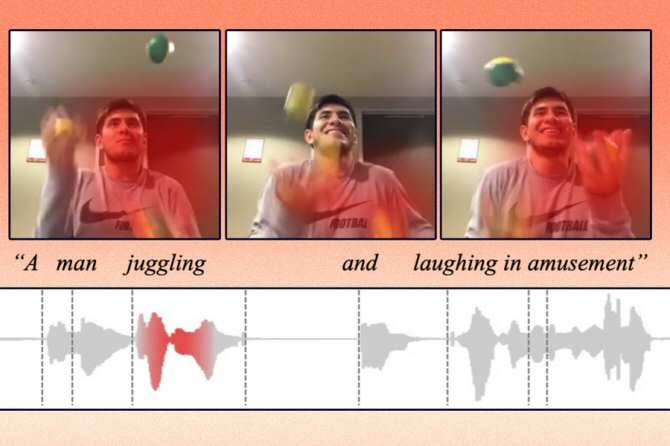
El equipo de Alexander Liu, del Laboratorio de Ciencias de la Computación e Inteligencia Artificial (CSAIL), adscrito al Instituto Tecnológico de Massachusetts (MIT) en Estados Unidos, ha encontrado una solución para este problema. Él y sus colaboradores han desarrollado una técnica de inteligencia artificial que aprende a representar los datos de forma que capte los conceptos que comparten las modalidades visual y auditiva. Por ejemplo, su método puede aprender que la acción de un bebé llorando en un vídeo está relacionada con la palabra hablada “llorando” en un clip de audio.
A partir de este conocimiento, su modelo de aprendizaje automático (una forma de inteligencia artificial) puede identificar dónde y cuándo tiene lugar una determinada acción en un vídeo y etiquetarla.
La eficiencia del nuevo sistema es mejor que la de otros métodos de aprendizaje automático en tareas que consisten en encontrar un dato, como un vídeo, que coincida con la consulta de un usuario formulada de otra forma, como por ejemplo mediante el lenguaje hablado. Su modelo también facilita que los usuarios vean por qué la máquina cree que el vídeo seleccionado coincide con su consulta.
Esta técnica podría utilizarse algún día para ayudar a los robots a aprender conceptos del mundo real a través de la percepción, de un modo muy parecido a como lo hacemos los humanos.