
Esta IA ha leído a Shakespeare para saber qué parte de una obra escribió
Numerosos historiadores han intentado descubrir qué escenas de ‘Enrique VIII’ fueron escritas por el dramaturgo británico y cuáles por otro autor, John Fletcher. Ahora, un algoritmo de aprendizaje automático ha analizado el estilo de ambos para averiguar qué líneas elaboró cada uno.

Durante gran parte de su vida, William Shakespeare fue el dramaturgo de una compañía de teatro llamada King’s Men que presentaba sus obras en las orillas del río Támesis en Londres (Reino Unido). Cuando Shakespeare murió en 1616, la compañía necesitaba encontrar a un sustituto y recurrió a uno de los dramaturgos más prolíficos y famosos de la época, un hombre llamado John Fletcher.
La fama de Fletcher ha ido disminuyendo desde entonces. Pero en 1850, el analista literario James Spedding percibió similitudes notables entre las obras de Fletcher y partes de la obra Enrique VIII de Shakespeare. Spedding concluyó que Fletcher y Shakespeare debían haber colaborado en la creación de esa obra.
La evidencia proviene de los estudios de las idiosincrasias lingüísticas de cada autor y de cómo se presentan en Enrique VIII. Por ejemplo, Fletcher a menudo escribe ye en lugar de you (tú) y ‘em en vez de them (los, las o les). También solía añadir la palabra sir (señor), still (todavía) y next (siguiente) a una línea de un pentámetro estándar para crear una sexta sílaba adicional.
Estas características permitieron que Spedding y otros analistas sugirieran que Fletcher debió haber estado implicado. Sin embargo, cómo se dividió la obra exactamente es un tema muy debatido. Además, otros críticos literarios han sugerido que otro dramaturgo inglés, Philip Massinger, era en realidad el coautor de Shakespeare.
Es por eso que a los analistas e historiadores les encantaría determinar, de una vez por todas, quién escribió qué partes de Enrique VIII.
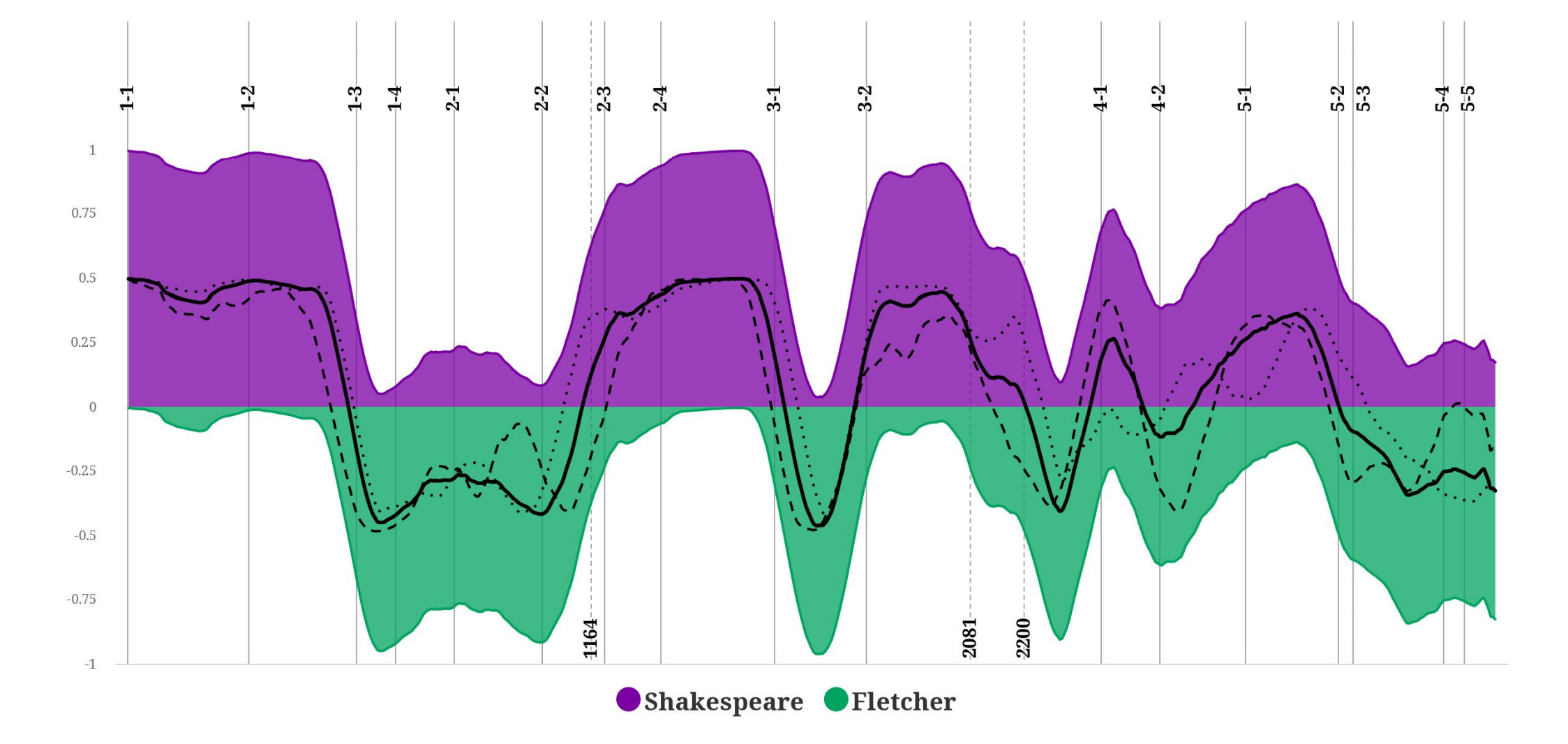
El investigador de la Academia Checa de Ciencias en Praga (República Checa) Petr Plecháč afirma que ha resuelto este problema mediante el aprendizaje automático con el fin de identificar la autoría de casi cada línea de la obra. “Nuestros resultados apoyan en gran medida la división canónica de la obra entre William Shakespeare y John Fletcher propuesta por James Spedding”, subraya Plecháč.
Este nuevo enfoque es sencillo en principio. Los algoritmos de aprendizaje automático se han utilizado durante los últimos años para identificar patrones distintivos en la forma en que escriben los autores.
La técnica utiliza un corpus del trabajo del autor para entrenar el algoritmo y otro corpus de trabajo diferente y más pequeño para probarlo. Sin embargo, debido a que el estilo literario de un escritor puede cambiar a lo largo de su vida, resulta importante asegurarse de que todas las obras tengan el mismo estilo.
Cuando el algoritmo ha aprendido el estilo, es decir, las palabras más utilizadas y los patrones rítmicos, es capaz de reconocerlo en textos que nunca antes ha visto.
Plecháč sigue exactamente esta técnica. Primero entrena el algoritmo para reconocer el estilo de Shakespeare usando otras obras escritas en la misma época que Enrique VIII. Estas obras son La tragedia de Coriolano, La tragedia de Cimbelino, El cuento de invierno y La tempestad.
Después, entrena al algoritmo para reconocer el trabajo de John Fletcher usando las obras de teatro que escribió en esa época: Valentiniano, Monsieur Thomas, El premio de la mujer y Bonduca.
Finalmente, ha pedido al algoritmo analizar la obra Enrique VIII y determinar el autor del texto usando la técnica de ventana deslizante para desplazarse por la obra.
Los resultados son interesantes. Coinciden con el análisis de Spedding sobre que Fletcher escribió algunas escenas que representan casi la mitad de la obra. Sin embargo, el algoritmo permite una aproximación más detallada que revela cómo la autoría a veces cambia no solo en las escenas nuevas, sino también en el final de las anteriores. Por ejemplo, en el Acto 3, Escena 2, el modelo sugiere una autoría mixta después de la línea 2081 e indica que Shakespeare se hace cargo por completo a partir de la línea 2200, antes del comienzo del Acto 4, Escena 1.
Plecháč también entrenó a su modelo para reconocer el trabajo de Philip Massinger, pero ha detectado pocas pruebas de su participación. “La participación de Philip Massinger es bastante improbable”, concluye.
Es así un trabajo interesante que muestra cómo los lingüistas y los analistas literarios utilizan el aprendizaje automático para comprender mejor nuestro pasado literario.
Sin embargo, hay muchas mejoras por delante. Por ejemplo, cuando los algoritmos de visión artificial han sido entrenados para reconocer el estilo artístico, los informáticos descubrieron rápidamente cómo extraer un estilo y lo aplican a otras imágenes, utilizando una técnica conocida como transferencia de estilo neuronal. De la noche a la mañana, se ha hecho posible que una fotografía simple tenga el estilo de Van Gogh o Monet.
Esto plantea la pregunta de si también sería posible una técnica similar para el texto. ¿Se podría transformar un ensayo e incluso un artículo de MIT Technology Review al estilo de Shakespeare o John Fletcher, por ejemplo?
Lamentablemente, más allá de la forma trivial de reemplazar palabras como them por ‘em y ejemplos similares, todavía no es posible. Esto se debe en gran medida a que los lingüistas o sus cargas algorítmicas no comprenden suficientemente la estructura subyacente de la comunicación.