Discurso sintético generado a partir de grabaciones cerebrales
La nueva tecnología es un trampolín para una prótesis de habla neural, según los investigadores.
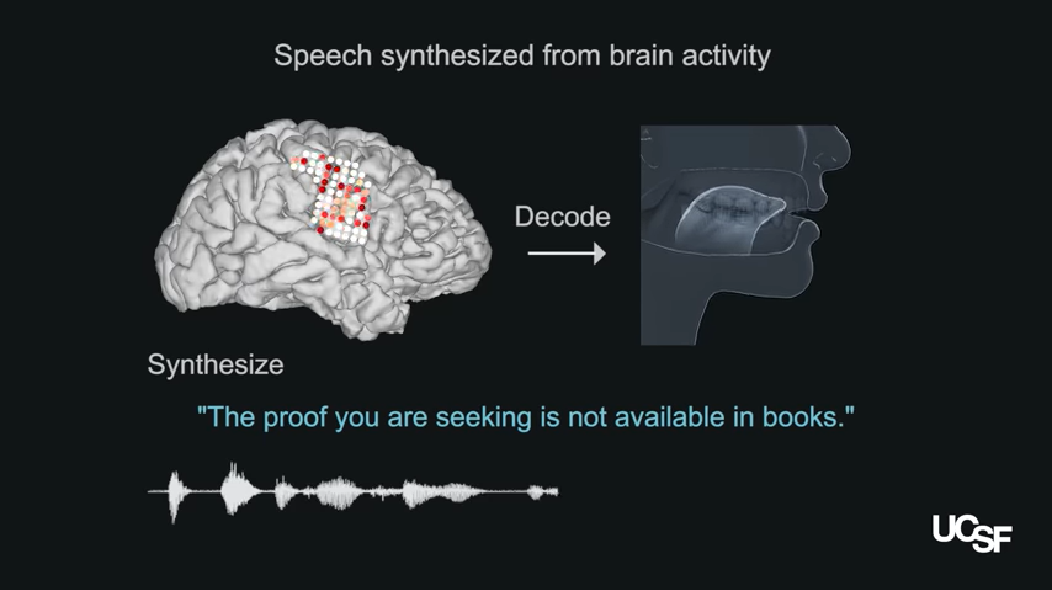
Una interfaz cerebro-máquina de última generación creada por los neurocientíficos de la UC San Francisco puede generar un discurso sintético de sonido natural mediante el uso de la actividad cerebral para controlar un tracto vocal virtual: una simulación por computadora anatómicamente detallada que incluye los labios, la mandíbula, la lengua y la laringe. . El estudio se realizó en participantes de investigación con habla intacta, pero la tecnología podría algún día restaurar las voces de las personas que han perdido la capacidad de hablar debido a la parálisis y otras formas de daño neurológico.
El accidente cerebrovascular, la lesión cerebral traumática y las enfermedades neurodegenerativas como la enfermedad de Parkinson, la esclerosis múltiple y la esclerosis lateral amiotrófica (ELA o enfermedad de Lou Gehrig) a menudo causan una pérdida irreversible de la capacidad para hablar. Algunas personas con discapacidades del habla severas aprenden a deletrear sus pensamientos letra por letra utilizando dispositivos de asistencia que rastrean movimientos oculares muy pequeños o músculos faciales. Sin embargo, producir texto o voz sintetizada con tales dispositivos es laborioso, propenso a errores y dolorosamente lento, generalmente permitiendo un máximo de 10 palabras por minuto, en comparación con las 100 a 150 palabras por minuto de voz natural.

El nuevo sistema que se está desarrollando en el laboratorio de Edward Chang , MD, que se describe el 24 de abril de 2019 en Nature , demuestra que es posible crear una versión sintetizada de la voz de una persona que puede controlarse mediante la actividad de los centros del habla de su cerebro. En el futuro, este enfoque podría no solo restaurar la comunicación fluida a personas con discapacidades del habla severas, dicen los autores, sino que también podría reproducir parte de la musicalidad de la voz humana que transmite las emociones y la personalidad del hablante.
“Por primera vez, este estudio demuestra que podemos generar oraciones habladas completas basadas en la actividad cerebral de un individuo”, dijo Chang, profesor de cirugía neurológica y miembro del Instituto de Neurociencia Weill de la UCSF . “Esta es una prueba de principio estimulante de que con la tecnología que ya está a nuestro alcance, deberíamos poder construir un dispositivo que sea clínicamente viable en pacientes con pérdida del habla”.
El tracto vocal virtual mejora la síntesis del habla naturalista
La investigación fue dirigida por Gopala Anumanchipalli , PhD, científico del habla, y Josh Chartier, un estudiante graduado en bioingeniería en el laboratorio Chang . Se basa en un estudio reciente en el que la pareja describió por primera vez cómo los centros del habla del cerebro humano coreografían los movimientos de los labios, la mandíbula, la lengua y otros componentes del tracto vocal para producir un habla fluida.

A partir de ese trabajo, Anumanchipalli y Chartier se dieron cuenta de que los intentos anteriores para decodificar directamente el habla a partir de la actividad cerebral podrían haber tenido un éxito limitado debido a que estas regiones del cerebro no representan directamente las propiedades acústicas de los sonidos del habla, sino las instrucciones necesarias para coordinar los movimientos del cerebro. Boca y garganta durante el habla.
“La relación entre los movimientos del tracto vocal y los sonidos del habla que se producen es complicada”, dijo Anumanchipalli. “Razonamos que si estos centros de habla en el cerebro codifican movimientos en lugar de sonidos, deberíamos intentar hacer lo mismo para decodificar esas señales”.
En su nuevo estudio, Anumancipali y Chartier pidieron a cinco voluntarios que estaban siendo tratados en el Centro de Epilepsia de la UCSF (pacientes con habla intacta a los que se les habían implantado temporalmente electrodos en el cerebro para mapear la fuente de sus ataques en preparación para la neurocirugía) para leer varios cientos de oraciones en voz alta mientras los investigadores registraron la actividad de una región del cerebro que se sabe está involucrada en la producción del lenguaje.
Basados en las grabaciones de audio de las voces de los participantes, los investigadores utilizaron principios lingüísticos para aplicar técnicas de ingeniería inversa a los movimientos del tracto vocal necesarios para producir esos sonidos: juntar los labios aquí, apretar las cuerdas vocales, mover la punta de la lengua al techo del Boca, luego relajarla, y así sucesivamente.
Este mapeo detallado del sonido a la anatomía permitió a los científicos crear un tracto vocal virtual realista para cada participante que podría ser controlado por su actividad cerebral. Esto comprendía dos algoritmos de aprendizaje automático de “red neuronal”: un decodificador que transforma los patrones de actividad cerebral producidos durante el habla en movimientos del tracto vocal virtual, y un sintetizador que convierte estos movimientos del tracto vocal en una aproximación sintética de la voz del participante.
Los investigadores hallaron que el discurso sintético producido por estos algoritmos era significativamente mejor que el discurso sintético descodificado directamente de la actividad cerebral de los participantes sin la inclusión de simulaciones de las partes vocales de los oradores. Los algoritmos produjeron oraciones que eran comprensibles para cientos de oyentes humanos en las pruebas de transcripción en colaboración realizadas en la plataforma Amazon Mechanical Turk.
Al igual que ocurre con el habla natural, los transcriptores tuvieron más éxito cuando recibieron listas más cortas de palabras para elegir, como sería el caso de los cuidadores que están preparados para los tipos de frases o solicitudes que los pacientes pueden pronunciar. Los transcriptores identificaron con precisión el 69 por ciento de las palabras sintetizadas de las listas de 25 alternativas y transcribieron el 43 por ciento de las oraciones con perfecta precisión. Con 50 palabras más desafiantes para elegir, la precisión general de los transcriptores se redujo a 47 por ciento, aunque aún eran capaces de entender perfectamente el 21 por ciento de las oraciones sintetizadas.
“Todavía tenemos maneras de imitar perfectamente el lenguaje hablado”, reconoció Chartier. “Somos bastante buenos para sintetizar sonidos más lentos como ‘sh’ y ‘z’, así como para mantener los ritmos y las entonaciones del habla y el género y la identidad del hablante, pero algunos de los sonidos más abruptos como ‘b’s y’ p’s get un poco confuso Aún así, los niveles de precisión que producimos aquí serían una mejora asombrosa en la comunicación en tiempo real en comparación con lo que está disponible actualmente “.
Inteligencia Artificial, Lingüística y Neurociencia Impulsada Avance
Actualmente, los investigadores están experimentando con matrices de electrodos de mayor densidad y algoritmos de aprendizaje automático más avanzados que esperan que mejoren aún más el habla sintetizada. La siguiente prueba importante para la tecnología es determinar si alguien que no puede hablar podría aprender a usar el sistema sin poder entrenarlo con su propia voz y hacer que se generalice a cualquier cosa que desee decir.

Los resultados preliminares de uno de los participantes en la investigación del equipo sugieren que el sistema de base anatómica de los investigadores puede descodificar y sintetizar oraciones nuevas de la actividad cerebral de los participantes casi tan bien como las oraciones en las que se entrenó el algoritmo. Incluso cuando los investigadores proporcionaron el algoritmo con datos de actividad cerebral registrados, mientras que uno de los participantes simplemente articuló oraciones sin sonido, el sistema todavía podía producir versiones sintéticas inteligibles de las oraciones imitadas en la voz del orador.
Los investigadores también encontraron que el código neural para los movimientos vocales se superponía parcialmente entre los participantes, y que la simulación del tracto vocal de un sujeto de la investigación podría adaptarse para responder a las instrucciones neurales registradas en el cerebro de otro participante. Juntos, estos hallazgos sugieren que los individuos con pérdida del habla debido a un deterioro neurológico pueden aprender a controlar una prótesis de habla modelada en la voz de alguien con habla intacta.
“Las personas que no pueden mover sus brazos y piernas han aprendido a controlar las extremidades robóticas con sus cerebros”, dijo Chartier. “Tenemos la esperanza de que un día las personas con discapacidades del habla puedan aprender a hablar nuevamente utilizando este tracto vocal artificial controlado por el cerebro”.
Anumanchipalli agregó: “Estoy orgulloso de haber podido reunir la experiencia de neurociencia, lingüística y aprendizaje automático como parte de este importante hito para ayudar a los pacientes con discapacidad neurológica”.
Autores: Anumanchipalli y Chartier son co-primeros autores del nuevo estudio. Chang, investigador biomédico de Bowes en UCSF, profesor en el Departamento de Cirugía Neurológica y miembro del Instituto de Neurociencias Weill de UCSF, es el autor principal y correspondiente.
Financiamiento: esta investigación fue financiada principalmente por los Institutos Nacionales de la Salud (subvenciones DP2 OD008627 y U01 NS098971-01). Chang es un investigador Robertson de la New York Stem Cell Foundation. Esta investigación también fue apoyada por la New York Stem Cell Foundation, el Instituto Médico Howard Hughes, la Fundación McKnight, la Fundación Shurl y Kay Curci y la Fundación William K. Bowes.
Revelaciones: Los autores declaran no tener intereses en competencia.